
💡 Dieser Test wird in der RAID-0-Konfiguration durchgeführt, und basierend auf den Formeln reduzieren sich die IOPS und der Durchsatz um den Faktor 6 bei RAID 6.
Um die Datenbankleistung bei groß angelegten IoT-Workloads zu testen, haben wir ein Szenario geschaffen, das ganze 170.000 Datenpunktänderungen pro Sekunde erfordert – ein typisches Volumen für eine industrielle Umgebung, in der Echtzeit entscheidend ist. Mithilfe von Kafka haben wir identische Nachrichtenströme gleichzeitig in MariaDB und TimeScaleDB eingespeist. Ziel war es, ihre Fähigkeit zur Echtzeit-Datenaufnahme in einem direkten Vergleich zu messen und herauszufinden, welche Datenbank der Herausforderung gewachsen ist.
for i in {1..5000}; do
./kafka-producer-consumer -run-producer -msg-count 10000 -db mysql -dsn 'consumer:consumer@tcp(10.117.209.17:3306)/newdb' -devices-per-payload 20
sleep 30
done
Sobald Kafka begann, Nachrichten zu erzeugen, war der Unterschied sofort sichtbar: Auf der MariaDB-Seite stieg die Verzögerung rapide an. Die Datenbank konnte die Nachrichten nicht schnell genug verarbeiten, was zu einem immer größer werdenden Backlog führte. TimeScaleDB hingegen zeigte sich völlig unbeeindruckt – die Nachrichten wurden reibungslos und ohne spürbare Verzögerung verarbeitet. Dies bestätigte unsere vorherigen Benchmarks, bei denen TimeScaleDB eine Schreibgeschwindigkeit von rund 1,4 Millionen Zeilen pro Sekunde erreichte, während MariaDB bei etwa 140.000 Zeilen pro Sekunde an ihre Leistungsgrenze stieß.
| Concurrency | Datapoints | Write Per Seconds Without Comparison | Write Per Seconds With Comparison | |
|---|---|---|---|---|
| MariaDB | 24 Partitions, 24 Consumers | 285.196.800 | 182.818 dp/s | 140.211 dp/s |
| PostgreSQL | 24 Partitions, 24 Consumers | 285.196.800 | 1.296.349 dp/s | - |
| TimescaleDB | 24 Partitions, 24 Consumers | 285.196.800 | 1.425.948 dp/s | 1.425.948 dp/s |
Die untenstehende Grafik zeigt deutlich, wie schnell TimeScaleDB im Vergleich zu MariaDB Kafka-Nachrichten verarbeitet. Während TimeScaleDB eine konstante, schnelle Aufnahmegeschwindigkeit beibehält, kommt es bei MariaDB zu kontinuierlichen Lesevorgängen, wodurch die Performance zunehmend langsamer wird.
Die Partitionierungsstrategie und der Indexierungsansatz sind in MariaDB und TimescaleDB identisch, wobei beide Datenbanken 3-Stunden-Partitionen verwenden. Zudem nutzen beide Systeme Datenkompression und denselben zusammengesetzten Index auf den Spalten:created_dt,device_id und metric_id. (Damit ist die Grundlage für einen fairen Vergleich gelegt, und die Unterschiede in der Leistung sind auf die Architektur und Optimierung der jeweiligen Datenbanken zurückzuführen.)
#MariaDB Table Structure
CREATE TABLE `measurements` (
`device_id` bigint(20) NOT NULL,
`metric_id` bigint(20) NOT NULL,
`value` float DEFAULT NULL,
`created_dt` datetime DEFAULT NULL,
KEY `created_dt_idx` (`created_dt`,`device_id`,`metric_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_uca1400_ai_ci ROW_FORMAT=COMPRESSED
PARTITION BY RANGE COLUMNS(`created_dt`)
(PARTITION `pd10` VALUES LESS THAN ('2025-03-18 00:00:00') ENGINE = InnoDB,
PARTITION `pd11` VALUES LESS THAN ('2025-03-18 03:00:00') ENGINE = InnoDB,
PARTITION `pd12` VALUES LESS THAN ('2025-03-18 06:00:00') ENGINE = InnoDB,
PARTITION `pd13` VALUES LESS THAN ('2025-03-18 09:00:00') ENGINE = InnoDB,
...
#TimeScaleDB table structure
tscale=# \d+ measurements
Table "public.measurements"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+--------------------------+-----------+----------+---------+---------+-------------+--------------+-------------
device_id | bigint | | not null | | plain | | |
metric_id | bigint | | not null | | plain | | |
value | double precision | | | | plain | | |
created_dt | timestamp with time zone | | not null | | plain | | |
Indexes:
"ix_created_dt_metric_id" btree (created_dt, device_id, metric_id)
device_id, metric_id, value
Triggers:
ts_insert_blocker BEFORE INSERT ON measurements FOR EACH ROW EXECUTE FUNCTION _timescaledb_functions.insert_blocker()
Child tables: _timescaledb_internal._hyper_21_19717_chunk,
_timescaledb_internal._hyper_21_19718_chunk,
_timescaledb_internal._hyper_21_19719_chunk,
_timescaledb_internal._hyper_21_19720_chunk,
_timescaledb_internal._hyper_21_19721_chunk,
_timescaledb_internal._hyper_21_19722_chunk,
_timescaledb_internal._hyper_21_19723_chunk,
_timescaledb_internal._hyper_21_19724_chunk,
_timescaledb_internal._hyper_21_19725_chunk,
_timescaledb_internal._hyper_21_19726_chunk,
_timescaledb_internal._hyper_21_19727_chunk,
_timescaledb_internal._hyper_21_19729_chunk,
_timescaledb_internal._hyper_21_19731_chunk,
_timescaledb_internal._hyper_21_19733_chunk,
_timescaledb_internal._hyper_21_19735_chunk,
_timescaledb_internal._hyper_21_19747_chunk,
_timescaledb_internal._hyper_21_19748_chunk,
_timescaledb_internal._hyper_21_19749_chunk,
_timescaledb_internal._hyper_21_19750_chunk
Access method: heap
Der gesamte unkomprimierte Datensatz über einen Zeitraum von zwei Tagen hatte ein Volumen von etwa 2 TB. Nach der Aktivierung der Kompression konnte die Datenmenge in MariaDB auf 1,6 TB reduziert werden, während TimeScaleDB eine deutlich bessere Kompression erzielte und die Daten auf nur 158 GB schrumpfen ließ. (Dieser Unterschied zeigt die außergewöhnliche Effizienz von TimeScaleDB bei der Speicherung großer Datenmengen.)
#MariaDB partitions.
root@DB-SQL1:/var/lib/mysql/newdb# du -hs *|sort -h|tail -n5
107G measurements#P#pd27.ibd
107G measurements#P#pd28.ibd
109G measurements#P#pd31.ibd
121G measurements#P#pd17.ibd
122G measurements#P#pd16.ibd
...
MariaDB [newdb]> select partition_name,table_rows from information_schema.partitions where table_schema='newdb' and table_name='measurements' and table_rows > 0;
+----------------+------------+
| partition_name | table_rows |
+----------------+------------+
| pd15 | 562071497 |
| pd16 | 1628687396 |
| pd17 | 1536599407 |
| pd18 | 1068136479 |
| pd21 | 34313574 |
| pd22 | 8165603 |
| pd23 | 743143627 |
| pd24 | 1640047208 |
| pd25 | 1776811458 |
| pd26 | 1792313832 |
| pd27 | 1708297643 |
| pd28 | 1748603181 |
| pd31 | 1545356537 |
| pd32 | 1809878363 |
| pd33 | 526746341 |
| pd37 | 5409840 |
| pd38 | 1081898230 |
| pd41 | 1230311361 |
| pd42 | 35063831 |
+----------------+------------+
19 rows in set (0.002 sec)
#TimeScaleDB chunk sizes
chunk_name | size_before comp. | size after comp.
-----------------------+-------------------+---------------------
_hyper_21_19717_chunk | 63 GB | 4688 MB
_hyper_21_19718_chunk | 195 GB | 14 GB
_hyper_21_19719_chunk | 198 GB | 14 GB
_hyper_21_19720_chunk | 153 GB | 11 GB
_hyper_21_19721_chunk | 8178 MB | 577 MB
_hyper_21_19722_chunk | 1821 MB | 133 MB
_hyper_21_19723_chunk | 130 GB | 9701 MB
_hyper_21_19724_chunk | 197 GB | 14 GB
_hyper_21_19725_chunk | 194 GB | 14 GB
_hyper_21_19733_chunk | 191 GB | 14 GB
_hyper_21_19726_chunk | 196 GB | 14 GB
_hyper_21_19735_chunk | 54 GB | 4018 MB
_hyper_21_19727_chunk | 193 GB | 14 GB
_hyper_21_19731_chunk | 196 GB | 14 GB
_hyper_21_19729_chunk | 197 GB | 14 GB
_hyper_21_19747_chunk | 658 MB | 53 MB
_hyper_21_19748_chunk | 121 GB | 9066 MB
_hyper_21_19749_chunk | 193 GB | 14 GB
(18 rows)
Als wir die Performance bei Read-Abfragen untersucht haben, stellten wir fest, dass die Antwortzeiten von MariaDB sehr langsam waren - selbst bei Abfragen einer einer einzelnen Partition mit optimiertem Index. Im Gegensatz dazu lieferte imeScaleDB die Abfrageergebnisse konstant und zuverlässig innerhalb von Millisekunden. (Dieser Unterschied zeigt, wie TimeScaleDB die Abfrageperformance optimiert und eine nahezu sofortige Datenverarbeitung ermöglicht.)
Wir führten Tests mit der folgenden einfachen Abfrage durch und variierten dabei lediglich den Zeitraum, um die Performance zu messen:
SELECT device_id,count(1)
FROM measurements
WHERE created_dt BETWEEN '2025-03-18 16:01:16.385137+01' AND '2025-03-18 16:02:16.385137+01' and device_id IN (783,11,15)
GROUP BY device_id;
| Time Period | MariaDB | TimeScaleDB | TimeScaleDB is Faster |
|---|---|---|---|
| 1 Minutes | 26021ms | 6ms | 4,337x |
| 2 Minutes | 28231ms | 59ms | 479x |
| 5 Minutes | 2640000ms | 182ms | 14,505x |
| 10 Minutes | - | 239ms | |
| 1 Hour | - | 511ms | |
| 5 Hours | - | 1099ms |
Die Analyse der Ausführungspläne bestätigt, dass die Abfragen sowohl das Partition Pruning als auch den angegebenen zusammengesetzten Index effektiv nutzen.
# Explain plan from MariaDB
MariaDB [newdb]> explain SELECT device_id,count(1) FROM measurements WHERE created_dt BETWEEN '2025-03-18 16:01:16.385137+01' AND '2025-03-18 16:02:16.385137+01' and device_id IN (783,11,15) GROUP BY device_id \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: measurements
type: range
possible_keys: created_dt_idx
key: created_dt_idx
key_len: 14
ref: NULL
rows: 25512230
Extra: Using where; Using index; Using temporary; Using filesort
1 row in set, 2 warnings (0.001 sec)
tscale=# explain SELECT device_id,count(1)
FROM measurements
WHERE created_dt BETWEEN '2025-03-18 16:01:16.385137+01' AND '2025-03-18 16:02:16.385137+01' and device_id IN (783,11,15)
GROUP BY device_id;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=1.91..912.12 rows=1 width=16)
Group Key: _hyper_21_19718_chunk.device_id
-> Custom Scan (DecompressChunk) on _hyper_21_19718_chunk (cost=1.91..252.11 rows=132000 width=8)
Vectorized Filter: ((created_dt >= '2025-03-18 16:01:16.385137+01'::timestamp with time zone) AND (created_dt <= '2025-03-18 16:02:16.385137+01'::timestamp with time zone))
-> Index Scan using compress_hyper_22_19730_chunk_device_id_metric_id__ts_meta__idx on compress_hyper_22_19730_chunk (cost=0.43..252.11 rows=132 width=60)
Index Cond: ((device_id = ANY ('{783,11,15}'::bigint[])) AND (_ts_meta_min_1 <= '2025-03-18 16:02:16.385137+01'::timestamp with time zone) AND (_ts_meta_max_1 >= '2025-03-18 16:01:16.385137+01'::timestamp with time zone))
(6 rows)
Time: 2.144 ms
Anschließend richteten wir ein Grafana-Dashboard ein, um die Daten für bestimmte Geräte und Metriken zu visualisieren. Es zeigt sich erneut, Abfragen, die gegen TimeScaleDB ausgeführt wurden, laden schnell und zuverlässig, wohingegen ähnliche Abfragen gegen MariaDB regelmäßig fehlschlagen oder ablaufen. Die Abfrage, die zur Erstellung der Grafana-Visualisierung verwendet wurde, lautet wie folgt:
Die Abfrage, die zur Erstellung der Grafana-Visualisierung verwendet wurde, lautet wie folgt:
SELECT
time_bucket('${custom_interval:text}', created_dt) AS "time", -- Bucket the data into 1-minute intervals
CONCAT(d.route, '.', m.name) AS series_name,
AVG(value) AS value -- Compute the average value for each time bucket
FROM measurements mu
JOIN metrics m ON mu.metric_id = m.id
JOIN devices d ON mu.device_id = d.id
WHERE
$__timeFilter(created_dt) AND
device_id IN (${Device:csv}) AND
metric_id IN (${Metric:csv})
GROUP BY time, series_name -- Group by time (interval) and series name
ORDER BY time, series_name;
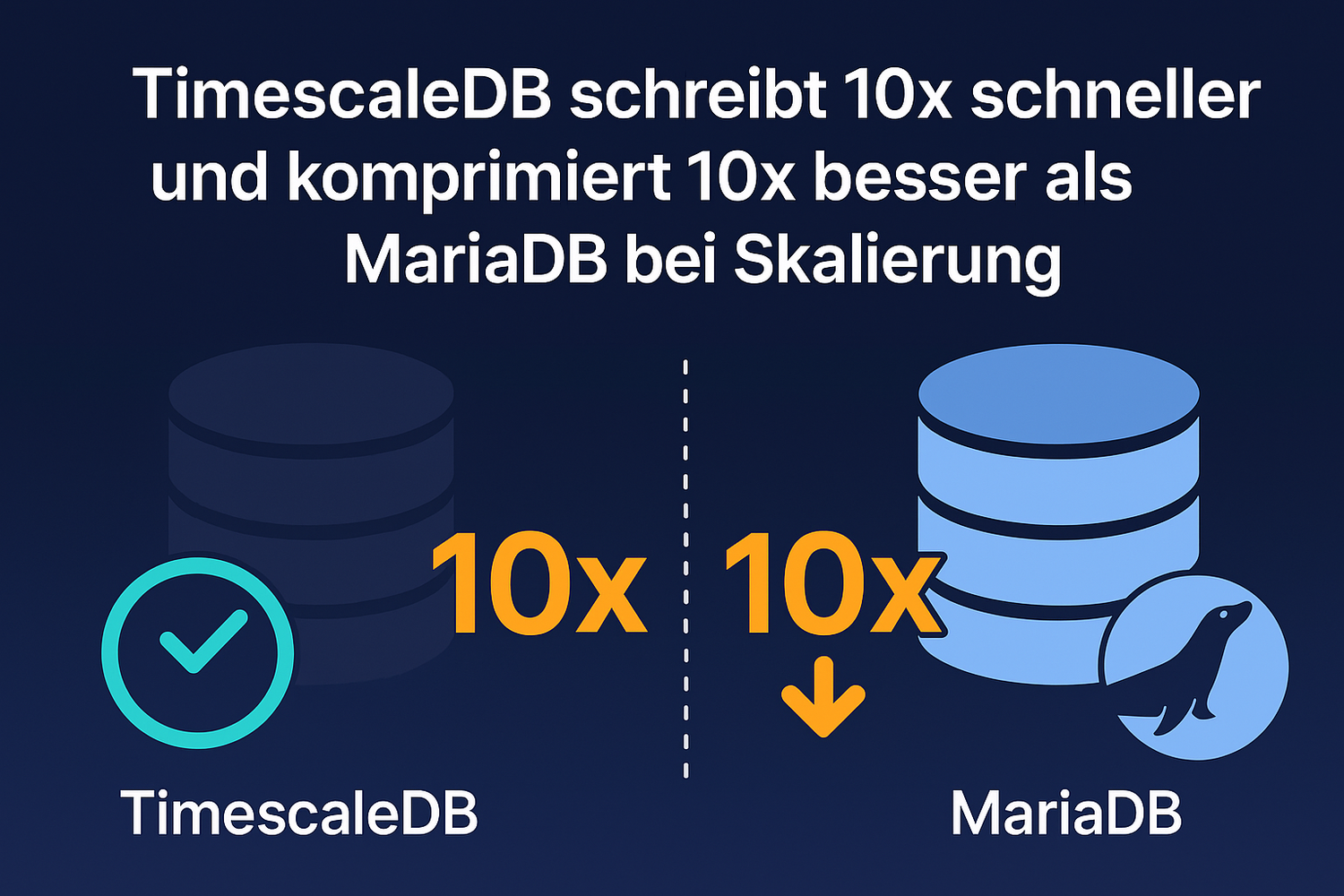
Unsere detaillierten Benchmarking-Ergebnisse zeigen eindeutig die erheblichen Vorteile einer Migration zu TimeScaleDB für groß angelegte, Echtzeit-IoT-Workloads im Vergleich zu traditionellen Lösungen wie MariaDB. Hier sind die wichtigsten Erkenntnisse basierend auf unseren gründlichen Tests:
Überlegene Schreib-Performance
Unter identischen Bedingungen erreichte TimeScaleDB einen Durchsatz von 1,4 Millionen Zeilen pro Sekunde, während MariaDB bei etwa 140.000 Zeilen pro Sekunde stagnierte. Dieser Unterschied macht TimeScaleDB etwa 10-mal schneller bei der Aufnahme von Daten aus Kafka-Streams.
Massive Kompressionseffizienz
TimeScaleDB übertraf MariaDB erheblich bei der Datenkompression. Über einen Zeitraum von 2 Tagen komprimierte TimeScaleDB 2 TB Rohdaten auf nur 158 GB, während MariaDB dasselbe Datenset auf lediglich 1,6 TB komprimieren konnte. Dies entspricht einer etwa 10-mal besseren Kompression und führt direkt zu erheblichen Einsparungen bei den Speicherbetriebskosten.
Echtzeit-Abfrageleistung
TimeScaleDB lieferte durchgehend Abfrageergebnisse in Millisekunden, selbst bei Abfragen über komplexe, indizierte Partitionen. Im vehementen Gegensatz dazu zeigte MariaDB eine schlechte Abfrageleistung, die häufig zu erheblichen Verzögerungen oder sogar Ausfällen bei der Nutzung von Echtzeit-Dashboards (z. B. Grafana-Visualisierungen) führte.
Effiziente Ressourcennutzung
Beide Datenbanken verwendeten identische Partitionierungsstrategien (3-Stunden-Partitionen) und Indexierungsschemata (created_dt,device_id, metric_id), was die Tatsache unterstreicht, dass die Leistungsverbesserungen von TimeScaleDB grundlegend auf seiner optimierten Architektur für Zeitreihendaten beruhen und nicht auf Konfigurationsunterschieden.
Warum das für Ihr Unternehmen wichtig ist
Kunden, die auf MariaDB oder andere allgemeine Datenbanken für intensive IoT-, Echtzeitüberwachungs- oder Analyse-Workloads angewiesen sind, laufen Gefahr, übermäßige Infrastrukturkosten, schlechte Leistung und betriebliche Engpässe zu erleiden. Der Umstieg auf TimeScaleDB bringt klare Vorteile:
Reduzierte Infrastrukturkosten dank deutlich besserer Kompression und effizienter Nutzung von Speicherressourcen.
Echtzeit-Reaktionsfähigkeit, die für einen Wettbewerbsvorteil in schnelllebigen industriellen, IoT- oder Analyseumgebungen entscheidend ist.
Zukunftssichere Skalierbarkeit, die Milliarden von Zeilen problemlos verarbeitet, ohne dass es zu Leistungseinbußen oder komplexen Wartungsaufwänden kommt.
Lassen Sie sich nicht durch die Einschränkungen Ihrer aktuellen Datenbank begrenzen. Kontaktieren Sie uns noch heute für eine individuelle Bewertung und beginnen Sie, die volle Power und Effizienz von TimeScaleDB zu nutzen.
Vielen Dank fürs Lesen! Haben Sie Probleme mit Ihrer Datenbank? Zögern Sie nicht, uns zu kontaktieren und besuchen Sie unsere Kontaktseite.


{kind=link}
Hinterlasse einen Kommentar
Alle Kommentare werden vor der Veröffentlichung geprüft.
Diese Website ist durch hCaptcha geschützt und es gelten die allgemeinen Geschäftsbedingungen und Datenschutzbestimmungen von hCaptcha.